以上文档基于python3
本节对Python的基础语法等内容进行整理和总结,特别是一些自己很容易忘记和弄错的地方。
认识python Python是一门脚本语言
Python变量 数据类型 数据类型官方文档
变量是存储在内存中的值,在创建变量时会在内存中开辟一个空间。
Python 中的变量赋值不需要类型声明。每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
Python3有六个标准的数据类型:
Python3 的六个标准数据类型中:
**不可变数据(3 个):**Number(数字)、String(字符串)、Tuple(元组);
**可变数据(3 个):**List(列表)、Dictionary(字典)、Set(集合)。
Python 共内置的 list、 tuple 、dict 和 set 四种基本集合,每个集合对象都能够迭代。
List操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 a = [1 ,2 ,3 ,4 ,1 ,1 ,-1 ] a.append(0 ) print (a)a = [1 ,2 ,3 ,4 ,1 ,1 ,-1 ] a.insert(1 ,0 ) print (a)a = [1 ,2 ,3 ,4 ,1 ,1 ,-1 ] a.remove(2 ) print (a)a = [1 ,2 ,3 ,4 ,1 ,1 ,-1 ] print (a[0 ]) print (a[-1 ]) print (a[0 :3 ]) print (a[5 :]) print (a[-3 :]) a = [1 ,2 ,3 ,4 ,1 ,1 ,-1 ] print (a.index(2 )) a = [4 ,1 ,2 ,3 ,4 ,1 ,1 ,-1 ] print (a.count(-1 ))a = [4 ,1 ,2 ,3 ,4 ,1 ,1 ,-1 ] a.sort() print (a)a.sort(reverse=True ) print (a)
多维列表 python中没有矩阵类型,常需要用多维list来进行操作。
在生成一个多维列表时有一个坑:
1 2 3 4 dim2list = [['a' ]* 3 ] * 3 dim2list = [['a' ]* 3 for i in range (3 )]
set 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 char_list = ['a' , 'b' , 'c' , 'c' , 'd' , 'd' , 'd' ] sentence = 'Welcome Back to This Tutorial' print (set (char_list))print (set (sentence))unique_char = set (char_list) unique_char.add('x' ) unique_char.remove('x' ) print (unique_char)unique_char.discard('d' ) print (unique_char)unique_char.clear() print (unique_char)unique_char = set (char_list) print (unique_char.difference({'a' , 'e' , 'i' }))print (unique_char.intersection({'a' , 'e' , 'i' }))
变量作用域 对于全局变量在函数内需要用global声明
输入和输出 1 2 3 4 5 6 print ()input ("please input sth." )int (input ("please input a number" ))
注意:2.7中的input(),的功能是读取用户输入的数字,3中input对应的是2.7中的raw_input(),功能是读取用户输入的字符串。
命令行传入参数 根据此文 整理
传入方式有多种:
Python 内置的命令行模块,主要就是 sys.argv 和 argparse
第三方模块,如 click 模块。
sys.argv 模块 argv=argument variable
argv[0]一般是被调用的脚本文件名或全路径,和操作系统有关,argv[1]和以后就是传入的数据了。S
用法示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import sysdef test_for_sys (year, name, body ): print ('the year is' , year) print ('the name is' , name) print ('the body is' , body) if __name__ == '__main__' : try : year, name, body = sys.argv[1 :4 ] test_for_sys(year, name, body) except Exception as e: print (sys.argv) print (e)
1 2 3 4 G:\Allcodes \testscripts >python test_cmd.py 2018 Leijun "are you ok ?" the year is 2018the name is Leijun the body is are you ok ?
如果参数不全会报错,参数多了则不会。
sys.argv 传入的参数是一个有序的列表,比较适合脚本中需要的参数个数很少且参数固定的脚本。
argparse 模块 用法示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import argparsedef test_for_sys (year, name, body ): print ('the year is' , year) print ('the name is' , name) print ('the body is' , body) parser = argparse.ArgumentParser(description='Test for argparse' ) parser.add_argument('--name' , '-n' , help ='name 属性,非必要参数' ) parser.add_argument('--year' , '-y' , help ='year 属性,非必要参数,但是有默认值' , default=2017 ) parser.add_argument('--body' , '-b' , help ='body 属性,必要参数' , required=True ) args = parser.parse_args() if __name__ == '__main__' : try : test_for_sys(args.year, args.name, args.body) except Exception as e: print (e)
1 2 3 4 5 6 7 8 9 10 G:\Allcodes\testscripts>python test_cmd.py --help usage: test_cmd.py [-h] [--name NAME] [--year YEAR] --body BODY Test for argparse optional arguments: -h, --help show this help message and exit --name NAME, -n NAME name 属性,非必要参数 --year YEAR, -y YEAR year 属性,非必要参数,但是有默认值 --body BODY, -b BODY body 属性,必要参数
可以看出 argparse 模块的功能更加完整,参数输入顺序灵活,且可以对每个输入测参数做规则限定。
click 库
Click 是 Flask 的团队 pallets 开发的优秀开源项目,它为命令行工具的开发封装了大量方法,使开发者只需要专注于功能实现。这是一个第三方库,专门为了命令行而生的非常有名的 Python 命令行模块。
用法示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import click@click.command() @click.option('--name' ,default='Leijun' ,help ='name 参数,非必须,有默认值' @click.option('--year' ,help ='year 参数' ,type =int @click.option('--body' ,help ='body 参数' def test_for_sys (year, name, body ): print ('the year is' , year) print ('the name is' , name) print ('the body is' , body) if __name__ == '__main__' : test_for_sys()
数学运算 基础的四则运算不说了,一些需要注意的是:
1 2 3 4 5 6 7 8 9 10 11 a**b pow (a, b)abs ()round ()import math math.floor(5.14 ) math.sqrt(16 )
python自身解决了很多数据类型的问题,比如整数溢出。
迭代器 Python 中的 for 句法实际上实现了设计模式中的迭代器模式 ,所以我们自己也可以按照迭代器的要求自己生成迭代器对象,以便在 for 语句中使用。 只要类中实现了 __iter__ 和 __next__ 函数,那么对象就可以在 for 语句中使用。 现在创建 Fibonacci 迭代器对象,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Fib (object ): def __init__ (self, max ): self .max = max self .n, self .a, self .b = 0 , 0 , 1 def __iter__ (self ): return self def __next__ (self ): if self .n < self .max : r = self .b self .a, self .b = self .b, self .a + self .b self .n = self .n + 1 return r raise StopIteration() for i in Fib(5 ): print (i)
生成器 除了使用迭代器以外,Python 使用 yield 关键字也能实现类似迭代的效果,yield 语句每次 执行时,立即返回结果给上层调用者,而当前的状态仍然保留,以便迭代器下一次循环调用。这样做的 好处是在于节约硬件资源,在需要的时候才会执行,并且每次只执行一次。
1 2 3 4 5 6 7 8 9 10 11 def fib (max a, b = 0 , 1 while max : r = b a, b = b, a+b max -= 1 yield r for i in fib(5 ): print (i)
循环 while 1 2 while condition: expressions
condition可以是除了比较操作(>, >=, <, <=)之外还可以是:
1 2 3 4 a = range (10 ) while a: print (a[-1 ]) a = a[:len (a)-1 ]
for 1 2 for item in sequence: expressions
sequence 为可迭代的对象,item 为序列中的每个对象。
和for循环经常一起用的是range函数(是Python 的内置工厂函数,也即调用实际是生成了一个类的实例)
1 range (start, stop[, step])
if判断 简单内容省去。
python中三目运算符的实现:python 可以通过 if-else 的行内表达式完成类似 condition ? value1 : value2 的功能。
1 var = var1 if condition else var2
函数 注意:注意所有的默认参数(用=附默认值)都不能出现在非默认参数的前面。
函数参数分:必须参数、默认参数、可变参数(不定长参数,*argv)、关键字参数(如传入的参数是一个字典,**argv)、组合参数,总共5种。
注意:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 school_info = {'school_name' : 'CQU' , 'class' : 'No. 1' , 'student_number' :'123' } def personal_info1 (name, gender, **school_info ): print (name, gender, school_info) personal_info1('ciel' , 'female' , **school_info) def personal_info2 (name, gender, *school_info ): print (name, gender, school_info) personal_info2('ciel' , 'female' , *school_info) def personal_info3 (name, gender, *school_info ): print (name, gender, school_info) personal_info3('ciel' , 'female' , school_info)
类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Calculator : name='Good Calculator' price=18 def add (self,x,y ): print (self .name) result = x + y print (result) def minus (self,x,y ): result=x-y print (result) def times (self,x,y ): print (x*y) def divide (self,x,y ): print (x/y) cal=Calculator()
init 初始化class的变量
1 2 3 4 5 6 7 8 9 10 11 class Calculator : name='good calculator' price=18 def __init__ (self,name,price,hight=10 ,width=14 ,weight=16 ): self .name=name self .price=price self .h=hight self .wi=width self .we=weight c=Calculator('bad calculator' ,18 )
模块 第三方模块通过pip包管理器进行安装
1 2 3 4 5 6 # 安装 pip install XXX # 更新 pip install -U XXX # 卸载 pip uninstall XXX
import 三种方式:
1 2 3 import xxximport xxx as xfrom xxx import x
运用自己的模块也一样调用,可以也将自己的脚本存储到路径site-packages中。
文件操作 转义字符 \n换行,\ttab效果,示例:
1 2 text = "this is a text. \nthis is a text. \n\t this is a text" print (text)
打印效果:
1 2 3 this is a text. this is a text. this is a text
读写txt文件 Python内置了读写文件的函数open()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 file = open ('file_name.txt' , 'w' ) file.write(text) file.close() file= open ('file_name.txt' ,'r' ) content=file.read() print (content)file= open ('my file.txt' ,'r' ) content=file.readline() print (content)
模式总结
模式
描述
w
write
r
read
a
append
r+
以读写方式打开,可对文件进行读写
w+
清除文件后,以读写方式打开,可对文件进行读写
a+
以读写方式打开文件,并把文件指针一道文件尾部。
b
以二进制模式打开文件,而不是文本形式。该模式只对Windows和Dos有效,类Unix的文件时用二进制模式进行操作的。
编码问题 1 2 3 f = open ('/Users/michael/gbk.txt' , 'r' , encoding='gbk' , errors='ignore' )
with open语句 由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
1 2 3 4 5 6 try : f = open ('/path/to/file' , 'r' ) print (f.read()) finally : if f: f.close()
但是每次都这么写实在太繁琐,所以,Python引入了with语句来自动帮我们调用close()方法:
1 2 with open('/path/to/file' , 'r' ) as f: print (f.read())
这和前面的try ... finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
读写csv文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import csv with open ('test.csv' ,'w' ) as csvFile: writer = csv.writer(csvFile) writer.writerow(["index" ,"a_name" ,"b_name" ]) writer.writerows([[1 ,2 ,3 ],[0 ,1 ,2 ],[4 ,5 ,6 ]]) with open ('test.csv' ,'r' ) as csvFile: reader = csv.reader(csvFile) for line in reader: print line
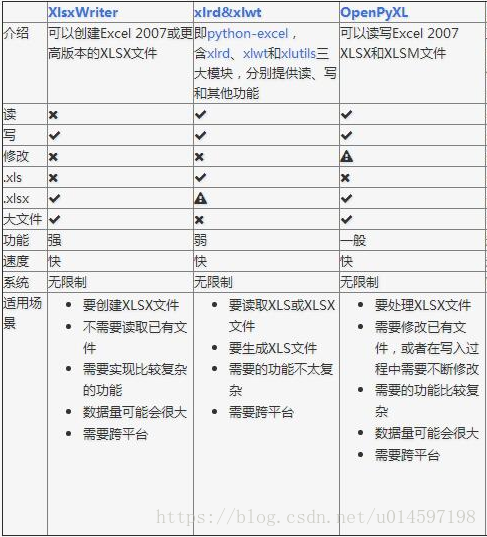
读写excel文件 python读写excel的方式有很多,比较如下:
文件读写更多高级内容见此文
其他 错误处理 1 2 3 4 5 6 7 try : file=open ('eeee.txt' ,'r' ) except Exception as e: print (e) """ [Errno 2] No such file or directory: 'eeee.txt' """
自定义的处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 try : file=open ('eeee.txt' ,'r+' ) except Exception as e: print (e) response = input ('do you want to create a new file:' ) if response=='y' : file=open ('eeee.txt' ,'w' ) else : pass else : file.write('ssss' ) file.close() """ [Errno 2] No such file or directory: 'eeee.txt' do you want to create a new file:y ssss #eeee.txt中会写入'ssss'
常用函数 zip zip函数接受任意多个(包括0个和1个)序列作为参数,合并 后返回一个tuple列表,请看示例:
1 2 3 4 5 6 7 a=[1 ,2 ,3 ] b=[4 ,5 ,6 ] ab=zip (a,b) print (list (ab)) """ [(1, 4), (2, 5), (3, 6)] """
lambda lambda定义一个简单的函数,实现简化代码的功能,看代码会更好理解。
fun = lambda x,y : x+y, 冒号前的x,y为自变量,冒号后x+y为具体运算。
1 2 3 4 5 6 7 8 9 10 fun= lambda x,y:x+y x=int (input ('x=' )) y=int (input ('y=' )) print (fun(x,y))""" x=6 y=6 12 """
map map根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素 调用 function 函数,返回包含每次 function 函数返回值的新列表。
1 map (function, iterable, ...)
示例:
1 2 3 4 5 6 7 8 9 10 11 >>>def square (x ) : ... return x ** 2 ... >>> map (square, [1 ,2 ,3 ,4 ,5 ]) [1 , 4 , 9 , 16 , 25 ] >>> map (lambda x: x ** 2 , [1 , 2 , 3 , 4 , 5 ]) [1 , 4 , 9 , 16 , 25 ] >>> map (lambda x, y: x + y, [1 , 3 , 5 , 7 , 9 ], [2 , 4 , 6 , 8 , 10 ])[3 , 7 , 11 , 15 , 19 ]
copy & deepcopy 浅复制 & 深复制 id是对象在CPython解释器里的地址
1 2 3 4 5 6 7 8 9 a = [1 ,2 ,[3 ,4 ]] b = a import copyc = copy.copy(a) d = copy.deepcopy(a)
reduce reduce()函数会对参数序列中元素进行累积。
1 2 3 4 5 reduce(function, iterable[, initializer]) >>> arr1 = [1 , 2 , 3 , 4 , 5 ]>>> reduce(lambda x,y: x+y, arr1)15
pickle&json python中有两个用于序列化的模块:
他们都提供四个功能:dumps,dump,loads,load
pickle模块可以将任意的对象序列化成二进制的字符串写入到文件中。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import picklea_dict = {'da' : 111 , 2 : [23 ,1 ,4 ], '23' : {1 :2 ,'d' :'sad' }} file = open ('pickle_example.pickle' , 'wb' ) pickle.dump(a_dict, file) file.close() with open ('pickle_example.pickle' , 'rb' ) as file: a_dict1 =pickle.load(file) print (a_dict1)
JSON.DUMP(S) & JSON.LOAD(S)
区别:dump&load是直接写入文件或者从文件读出
执行
What does if name == “main ”: do?
References 莫烦PYTHON
Python开发 之 Python3读写Excel文件(较全)